 首页
首页  导航
导航




DeepSeek令人惊讶的负担得起的AI模型挑战了行业巨头。该公司声称已经培训了其强大的DeepSeek V3神经网络,仅利用2048 GPU,这与竞争对手的支出形成了鲜明的对比。但是,该数字仅反映了培训前的GPU成本,省略了大量研究,改进,数据处理和基础设施费用。
 图像:ensigame.com
图像:ensigame.com
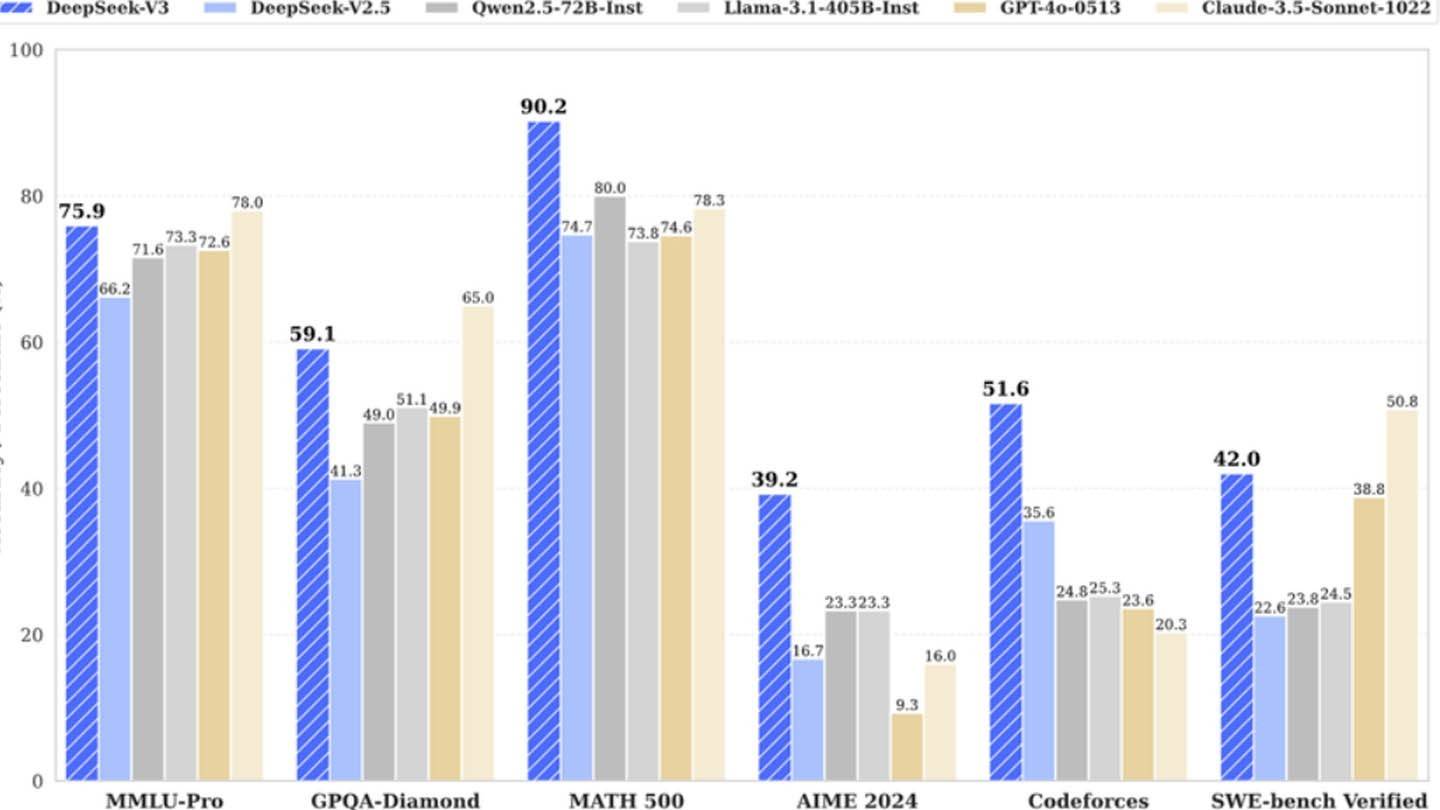
DeepSeek的创新技术将其区分开来。关键特征包括用于同时单词预测的多言论预测(MTP),专家的混合(MOE)利用256个神经网络来增强处理,以及多头潜在注意力(MLA)(MLA),以改善信息提取。这些进步有助于模型的准确性和效率。
 图像:ensigame.com
图像:ensigame.com
与公开的600万美元数字相反,半分析显示,DeepSeek的大规模基础设施约为50,000 Nvidia Hopper GPU,价值约16亿美元,运营成本达到9.44亿美元。这项大量投资,加上其研究人员的高薪(每年超过130万美元),吸引了中国大学的顶尖人才。该公司的自我资助性质和精简结构有助于其敏捷性和快速创新。
 图像:ensigame.com
图像:ensigame.com
尽管DeepSeek的“预算友好”主张具有误导性,但其在AI开发中的总投资超过5亿美元,再加上其技术突破和熟练的劳动力,使其可以有效竞争。培训成本的比较进一步凸显了这一点:DeepSeek的R1售价500万美元,而Chatgpt 4据说耗资1亿美元,表明了巨大的成本优势,甚至考虑了DeepSeek的实际投资。
 图像:ensigame.com
图像:ensigame.com
DeepSeek的成功强调了资金庞大,独立的AI公司挑战已建立的参与者的潜力。但是,它的成就源于大量投资,技术进步和高技能的团队,使最初的“低成本”叙述变得过分简化。
 最新文章
最新文章










 最新游戏
最新游戏

![Faded Bonds – Version 0.1 [Whispering Studios]](https://imgs.xddxz.com/uploads/28/1719578752667eb080ac522.jpg)









